|
|
Version: 0.6.0 |


The JSON parser. More...
Public Member Functions | |
| wxJSONReader (int flags=wxJSONREADER_TOLERANT, int maxErrors=30) | |
| Ctor. More... | |
| virtual | ~wxJSONReader () |
| Dtor - does nothing. | |
| int | Parse (const wxString &doc, wxJSONValue *val) |
| Parse the JSON document. More... | |
| int | Parse (wxInputStream &doc, wxJSONValue *val) |
| int | GetDepth () const |
| Return the depth of the JSON input text. More... | |
| int | GetErrorCount () const |
| Return the size of the error message's array. | |
| int | GetWarningCount () const |
| Return the size of the warning message's array. | |
| const wxArrayString & | GetErrors () const |
| Return a reference to the error message's array. | |
| const wxArrayString & | GetWarnings () const |
| Return a reference to the warning message's array. | |
Static Public Member Functions | |
| static int | UTF8NumBytes (char ch) |
| Compute the number of bytes that makes a UTF-8 encoded wide character. More... | |
Protected Member Functions | |
| int | DoRead (wxInputStream &doc, wxJSONValue &val) |
| Reads the JSON text document (internal use) More... | |
| void | AddError (const wxString &descr) |
| Add a error message to the error's array. More... | |
| void | AddError (const wxString &fmt, const wxString &str) |
| void | AddError (const wxString &fmt, wxChar ch) |
| void | AddWarning (int type, const wxString &descr) |
| Add a warning message to the warning's array. More... | |
| int | GetStart (wxInputStream &is) |
| Returns the start of the document. More... | |
| int | ReadChar (wxInputStream &is) |
| Read a character from the input JSON document. More... | |
| int | PeekChar (wxInputStream &is) |
| Peek a character from the input JSON document. More... | |
| void | StoreValue (int ch, const wxString &key, wxJSONValue &value, wxJSONValue &parent) |
| Store a value in the parent object. More... | |
| int | SkipWhiteSpace (wxInputStream &is) |
| Skip all whitespaces. More... | |
| int | SkipComment (wxInputStream &is) |
| Skip a comment. More... | |
| void | StoreComment (const wxJSONValue *parent) |
| Store the comment string in the value it refers to. More... | |
| int | ReadString (wxInputStream &is, wxJSONValue &val) |
| Read a string value. More... | |
| int | ReadToken (wxInputStream &is, int ch, wxString &s) |
| Reads a token string. More... | |
| int | ReadValue (wxInputStream &is, int ch, wxJSONValue &val) |
| Read a value from input stream. More... | |
| int | ReadUES (wxInputStream &is, char *uesBuffer) |
| Read a 4-hex-digit unicode character. More... | |
| int | AppendUES (wxMemoryBuffer &utf8Buff, const char *uesBuffer) |
| The function appends a Unice Escaped Sequence to the temporary UTF8 buffer. More... | |
| int | NumBytes (char ch) |
| Return the number of bytes that make a character in stream input. More... | |
| int | ConvertCharByChar (wxString &s, const wxMemoryBuffer &utf8Buffer) |
| Convert a UTF-8 memory buffer one char at a time. More... | |
| int | ReadMemoryBuff (wxInputStream &is, wxJSONValue &val) |
| Read a memory buffer type. More... | |
Protected Attributes | |
| int | m_flags |
| Flag that control the parser behaviour,. | |
| int | m_maxErrors |
| Maximum number of errors stored in the error's array. | |
| int | m_lineNo |
| The current line number (start at 1). | |
| int | m_colNo |
| The current column number (start at 1). | |
| int | m_level |
| The current level of object/array annidation (start at ZERO). | |
| int | m_depth |
| The depth level of the read JSON text. | |
| wxJSONValue * | m_current |
| The pointer to the value object that is being read. | |
| wxJSONValue * | m_lastStored |
| The pointer to the value object that was last stored. | |
| wxJSONValue * | m_next |
| The pointer to the value object that will be read. | |
| wxString | m_comment |
| The comment string read by SkipComment(). | |
| int | m_commentLine |
| The starting line of the comment string. | |
| wxArrayString | m_errors |
| The array of error messages. | |
| wxArrayString | m_warnings |
| The array of warning messages. | |
| int | m_peekChar |
| The character read by the PeekChar() function (-1 none) | |
| bool | m_noUtf8 |
| ANSI: do not convert UTF-8 strings. | |
Detailed Description
The JSON parser.
The class is a JSON parser which reads a JSON formatted text and stores values in the wxJSONValue structure. The ctor accepts two parameters: the style flag, which controls how much error-tolerant should the parser be and an integer which is the maximum number of errors and warnings that have to be reported (the default is 30).
If the JSON text document does not contain an open/close JSON character the function returns an invalid value object; in other words, the wxJSONValue::IsValid() function returns FALSE. This is the case of a document that is empty or contains only whitespaces or comments. If the document contains a starting object/array character immediatly followed by a closing object/array character (i.e.: {} ) then the function returns an empty array or object JSON value. This is a valid JSON object of type wxJSONTYPE_OBJECT or wxJSONTYPE_ARRAY whose wxJSONValue::Size() function returns ZERO.
- JSON text
The wxJSON parser just skips all characters read from the input JSON text until the start-object '{' or start-array '[' characters are encontered (see the GetStart() function). This means that the JSON input text may contain anything before the first start-object/array character except these two chars themselves unless they are included in a C/C++ comment. Comment lines that apear before the first start array/object character, are non ignored if the parser is constructed with the wxJSONREADER_STORE_COMMENT flag: they are added to the comment's array of the root JSON value.
Note that the parsing process stops when the internal DoRead() function returns. Because that function is recursive, the top-level close-object '}' or close-array ']' character cause the top-level DoRead() function to return thus stopping the parsing process regardless the EOF condition. This means that the JSON input text may contain anything after the top-level close-object/array character. Here are some examples:
Returns a wxJSONTYPE_INVALID value (invalid JSON value)
Returns a wxJSONTYPE_OBJECT value of Size() = 0
Returns a wxJSONTYPE_ARRAY value of Size() = 0
Text before and after the top-level open/close characters is ignored.
- Extensions
The wxJSON parser recognizes all JSON text plus some extensions that are not part of the JSON syntax but that many other JSON implementations do recognize. If the input text contains the following non-JSON text, the parser reports the situation as warnings and not as errors unless the parser object was constructed with the wxJSONREADER_STRICT flag. In the latter case the wxJSON parser is not tolerant.
- C/C++ comments: the parser recognizes C and C++ comments. Comments can optionally be stored in the value they refer to and can also be written back to the JSON text document. To know more about comment storage see wxjson_comments
- case tolerance: JSON syntax states that the literals
null,trueandfalsemust be lowercase; the wxJSON parser also recognizes mixed case literals such as, for example, Null or FaLSe. A warning is emitted.
- wrong or missing closing character: wxJSON parser is tolerant about the object / array closing character. When an open-array character '[' is encontered, the parser expects the corresponding close-array character ']'. If the character encontered is a close-object char '}' a warning is reported. A warning is also reported if the character is missing when the end-of-file is reached.
- multi-line strings: this feature allows a JSON string type to be splitted in two or more lines as in the standard C/C++ languages. The drawback is that this feature is error-prone and you have to use it with care. For more info about this topic read wxjson_tutorial_style_split
Note that you can control how much error-tolerant should the parser be and also you can specify how many and what extensions are recognized. See the constructor's parameters for more details.
- Unicode vs ANSI
The parser can read JSON text from two very different kind of objects:
- a string object (wxString)
- a stream object (wxInputStream)
When the input is from a string object, the character represented in the string is platform- and mode- dependant; in other words, characters are represented differently: in ANSI builds they depend on the charset in use and in Unicode builds they depend on the platform (UCS-2 on win32, UCS-4 or UTF-8 on GNU/Linux).
When the input is from a stream object, the only recognized encoding format is UTF-8 for both ANSI and Unicode builds.
- Example:
Starting from version 1.1.0 the wxJSON reader and the writer has changed in their internal organization. To know more about ANSI and Unicode mode read wxjson_tutorial_unicode.
Constructor & Destructor Documentation
| wxJSONReader::wxJSONReader | ( | int | flags = wxJSONREADER_TOLERANT, |
| int | maxErrors = 30 |
||
| ) |
Ctor.
Construct a JSON parser object with the given parameters.
JSON parser objects should always be constructed on the stack but it does not hurt to have a global JSON parser.
- Parameters
-
flags this paramter controls how much error-tolerant should the parser be maxErrors the maximum number of errors (and warnings, too) that are reported by the parser. When the number of errors reaches this limit, the parser stops to read the JSON input text and no other error is reported.
The flag parameter is the combination of ZERO or more of the following constants OR'ed toghether:
- wxJSONREADER_ALLOW_COMMENTS: C/C++ comments are recognized by the parser; a warning is reported by the parser
- wxJSONREADER_STORE_COMMENTS: C/C++ comments, if recognized, are stored in the value they refer to and can be rewritten back to the JSON text
- wxJSONREADER_CASE: the parser recognizes mixed-case literal strings
- wxJSONREADER_MISSING: the parser allows missing or wrong close-object and close-array characters
- wxJSONREADER_MULTISTRING: strings may be splitted in two or more lines
- wxJSONREADER_COMMENTS_AFTER: if STORE_COMMENTS if defined, the parser assumes that comment lines apear before the value they refer to unless this constant is specified. In the latter case, comments apear after the value they refer to.
- wxJSONREADER_NOUTF8_STREAM: suppress UTF-8 conversion when reading a string value from a stream: the reader assumes that the input stream is encoded in ANSI format and not in UTF-8; only meaningfull in ANSI builds, this flag is simply ignored in Unicode builds.
You can also use the following shortcuts to specify some predefined flag's combinations:
- wxJSONREADER_STRICT: all wxJSON extensions are reported as errors, this is the same as specifying a ZERO value as
flags. - wxJSONREADER_TOLERANT: this is the same as ALLOW_COMMENTS | CASE | MISSING | MULTISTRING; all wxJSON extensions are turned on but comments are not stored in the value objects.
- Example:
The following code fragment construct a JSON parser, turns on all wxJSON extensions and also stores C/C++ comments in the value object they refer to. The parser assumes that the comments apear before the value:
Member Function Documentation
|
protected |
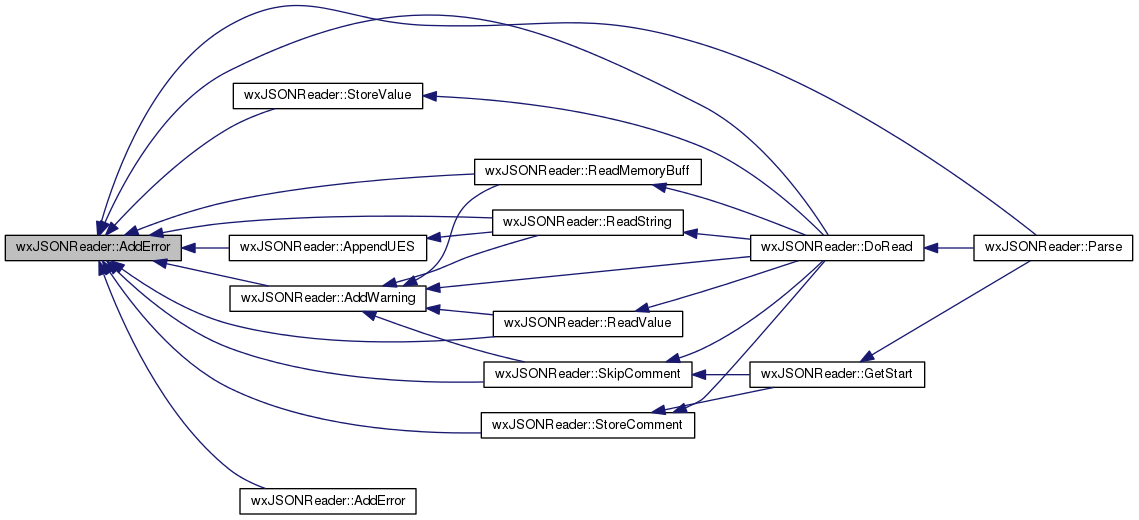
Add a error message to the error's array.
The overloaded versions of this function add an error message to the error's array stored in m_errors. The error message is formatted as follows:
The msg parameter is the description of the error; line's and column's number are automatically added by the functions. The fmt parameter is a format string that has the same syntax as the printf function. Note that it is the user's responsability to provide a format string suitable with the arguments: another string or a character.
|
protected |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.

|
protected |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.

|
protected |
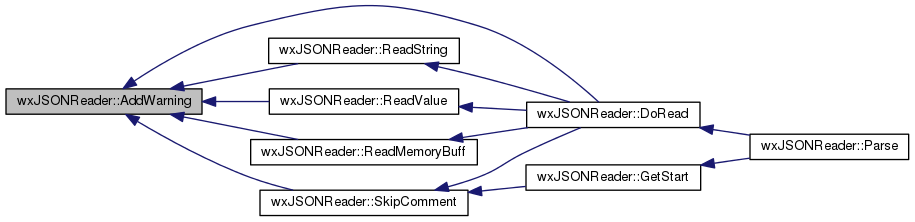
Add a warning message to the warning's array.
The warning description is as follows:
Warning messages are generated by the parser when the JSON text that has been read is not well-formed but the error is not fatal and the parser recognizes the text as an extension to the JSON standard (see the parser's ctor for more info about wxJSON extensions).
Note that the parser has to be constructed with a flag that indicates if each individual wxJSON extension is on. If the warning message is related to an extension that is not enabled in the parser's m_flag data member, this function calls AddError() and the warning message becomes an error message. The type parameter is one of the same constants that specify the parser's extensions. If type is ZERO than the function always adds a warning

|
protected |
The function appends a Unice Escaped Sequence to the temporary UTF8 buffer.
This function is called by ReadString() when a unicode escaped sequence is read from the input text as for example:
which represents a control character. The uesBuffer parameter contains the 4 hexadecimal digits that are read from ReadUES.
The function tries to convert the 4 hex digits in a wchar_t character which is appended to the memory buffer utf8Buff after converting it to UTF-8.
If the conversion from hexadecimal fails, the function does not store the character in the UTF-8 buffer and an error is reported. The function is the same in ANSI and Unicode. Returns -1 if the buffer does not contain valid hex digits. sequence. On success returns ZERO.
- Parameters
-
utf8Buff the UTF-8 buffer to which the control char is written uesBuffer the four-hex-digits read from the input text
- Returns
- ZERO on success, -1 if the four-hex-digit buffer cannot be converted


|
protected |
Convert a UTF-8 memory buffer one char at a time.
This function is used in ANSI mode when input from a stream is in UTF-8 format and the UTF-8 buffer read cannot be converted to the locale wxString object. The function performs a char-by-char conversion of the buffer and appends every representable character to the string s. Characters that cannot be represented are stored as unicode escaped sequences in the form:
where XXXX is a for-hex-digits Unicode code point. The function returns the number of characters that cannot be represented in the current locale.


|
protected |
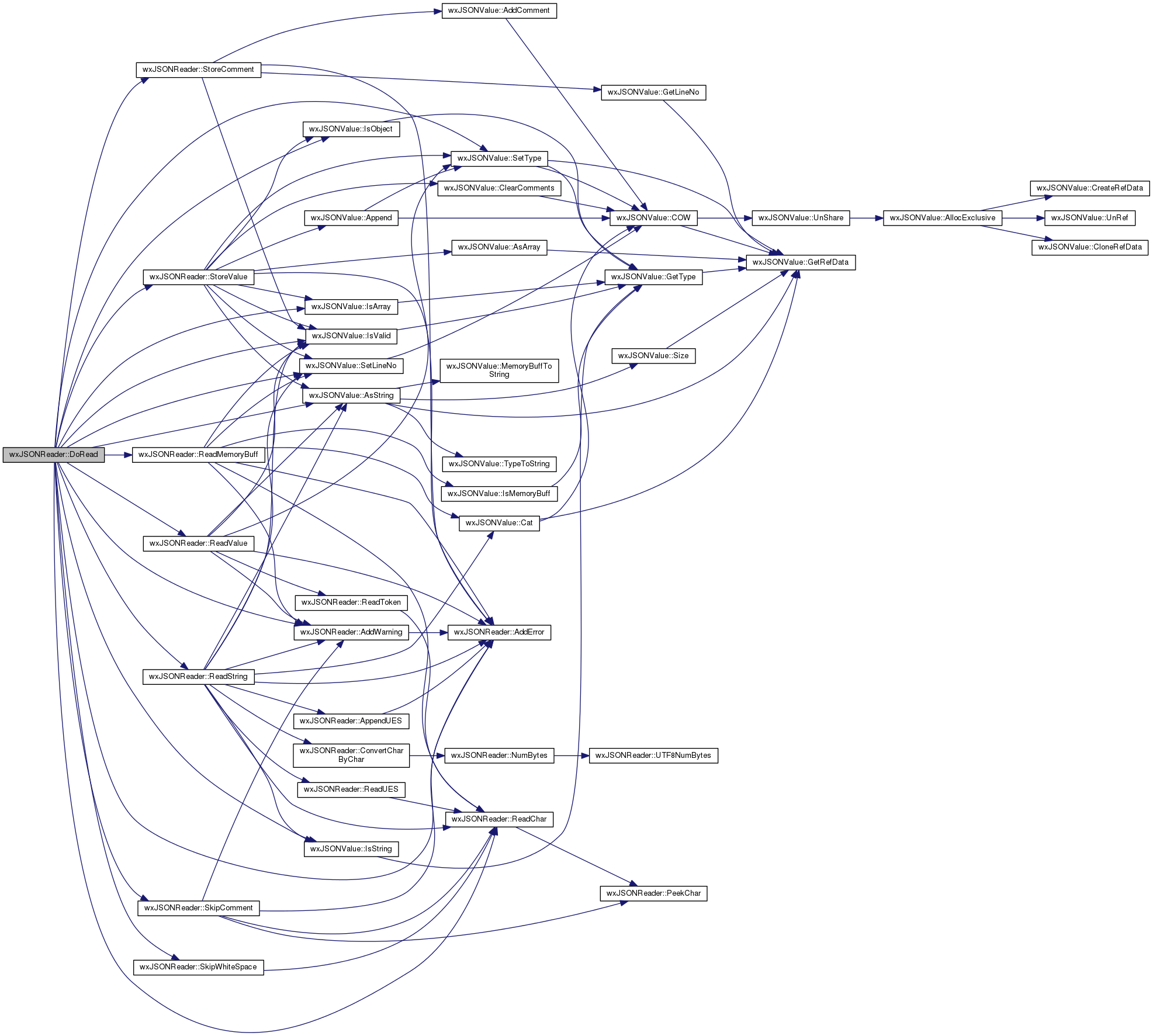
Reads the JSON text document (internal use)
This is a recursive function that is called by Parse() and by the DoRead() function itself when a new object / array character is encontered. The function returns when a EOF condition is encontered or when the corresponding close-object / close-array char is encontered. The function also increments the m_level data member when it is entered and decrements it on return. It also sets m_depth equal to m_level if m_depth is less than m_level.
The function is the heart of the wxJSON parser class but it is also very easy to understand because JSON syntax is very easy.
Returns the last close-object/array character read or -1 on EOF.
- Parameters
-
is the input stream that contains the JSON text parent the JSON value object that is the parent of all subobjects read by the function until the next close-object/array (for the top-level DoReadfunctionparentis the root JSON object)
- Returns
- one of close-array or close-object char or -1 on error or EOF

| int wxJSONReader::GetDepth | ( | ) | const |
Return the depth of the JSON input text.
The function returns the number of times the recursive DoRead function was called in the parsing process thus returning the maximum depth of the JSON input text.
|
protected |
Returns the start of the document.
This is the first function called by the Parse() function and it searches the input stream for the starting character of a JSON text and returns it. JSON text start with '{' or '['. If the two starting characters are inside a C/C++ comment, they are ignored. Returns the JSON-text start character or -1 on EOF.
- Parameters
-
is the input stream that contains the JSON text
- Returns
- -1 on errors or EOF; one of '{' or '['

|
protected |
Return the number of bytes that make a character in stream input.
This function returns the number of bytes that represent a unicode code point in various encoding. For example, if the input stream is UTF-32 the function returns 4. Because the only recognized format for streams is UTF-8 the function just calls UTF8NumBytes() and returns. The function is, actually, not used at all.


| int wxJSONReader::Parse | ( | const wxString & | doc, |
| wxJSONValue * | val | ||
| ) |
Parse the JSON document.
The two overloaded versions of the Parse() function read a JSON text stored in a wxString object or in a wxInputStream object.
If val is a NULL pointer, the function does not store the values: it can be used as a JSON checker in order to check the syntax of the document. Returns the number of errors found in the document. If the returned value is ZERO and the parser was constructed with the wxJSONREADER_STRICT flag, then the parsed document is well-formed and it only contains valid JSON text.
If the wxJSONREADER_TOLERANT flag was used in the parser's constructor, then a return value of ZERO does not mean that the document is well-formed because it may contain comments and other extensions that are not fatal for the wxJSON parser but other parsers may fail to recognize. You can use the GetWarningCount() function to know how many wxJSON extensions are present in the JSON input text.
Note that the JSON value object val is not cleared by this function unless its type is of the wrong type. In other words, if val is of type wxJSONTYPE_ARRAY and it already contains 10 elements and the input document starts with a '[' (open-array char) then the elements read from the document are appended to the existing ones.
On the other hand, if the text document starts with a '{' (open-object) char then this function must change the type of the val object to wxJSONTYPE_OBJECT and the old content of 10 array elements will be lost.
- Different input types
The real parsing process in done using UTF-8 streams. If the input is from a wxString object, the Parse function first converts the input string in a temporary wxMemoryInputStream which contains the UTF-8 conversion of the string itself. Next, the overloaded Parse function is called.
- Parameters
-
doc the JSON text that has to be parsed val the wxJSONValue object that contains the parsed text; if NULL the parser do not store anything but errors and warnings are reported
- Returns
- the total number of errors encontered
| int wxJSONReader::Parse | ( | wxInputStream & | is, |
| wxJSONValue * | val | ||
| ) |
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
|
protected |
Peek a character from the input JSON document.
This function just calls the Peek() function on the stream and returns it.
- Parameters
-
is the input stream that contains the JSON text
- Returns
- the next char (one single byte) in the input stream or -1 on error or EOF
|
protected |
Read a character from the input JSON document.
The function returns the next byte from the UTF-8 stream as an INT. In case of errors or EOF, the function returns -1. The function also updates the m_lineNo and m_colNo data members and converts all CR+LF sequence in LF.
This function only returns one byte UTF-8 (one code unit) at a time and not Unicode code points. The only reason for this function is to process line and column numbers.
- Parameters
-
is the input stream that contains the JSON text
- Returns
- the next char (one single byte) in the input stream or -1 on error or EOF

|
protected |
Read a memory buffer type.
This function is called by DoRead() when the single-quote character is encontered which starts a memory buffer type. This type is a wxJSON extension so the function emits a warning when such a type encontered. If the reader is constructed without the wxJSONREADER_MEMORYBUFF flag then the warning becomes an error. To know more about this JSON syntax extension read wxjson_tutorial_memorybuff
- Parameters
-
is the input stream val the JSON value that will hold the memory buffer value
- Returns
- the last char read or -1 in case of EOF

|
protected |
Read a string value.
The function reads a string value from input stream and it is called by the DoRead() function when it enconters the double quote characters. The function read all bytes up to the next double quotes (unless it is escaped) and stores them in a temporary UTF-8 memory buffer. Also, the function processes the escaped characters defined in the JSON syntax.
Next, the function tries to convert the UTF-8 buffer to a wxString object using the wxString::FromUTF8 function. Depending on the build mode, we can have the following:
- in Unicode the function always succeeds, provided that the buffer contains valid UTF-8 code units.
- in ANSI builds the conversion may fail because of the presence of unrepresentable characters in the current locale. In this case, the default behaviour is to perform a char-by-char conversion; every char that cannot be represented in the current locale is stored as unicode escaped sequence
- in ANSI builds, if the reader is constructed with the wxJSONREADER_NOUTF8_STREAM then no conversion takes place and the UTF-8 temporary buffer is simply copied to the wxString object
The string is, finally, stored in the provided wxJSONValue argument provided that it is empty or it contains a string value. This is because the parser class recognizes multi-line strings like the following one:
Because of the lack of the value separator (,) the parser assumes that the string was splitted into several double-quoted strings. If the value does not contain a string then an error is reported. Splitted strings cause the parser to report a warning.

|
protected |
Reads a token string.
This function is called by the ReadValue() when the first character encontered is not a special char and it is not a double-quote. The only possible type is a literal or a number which all lies in the US-ASCII charset so their UTF-8 encodeing is the same as US-ASCII. The function simply reads one byte at a time from the stream and appends them to a wxString object. Returns the next character read.
A token cannot include unicode escaped sequences so this function does not try to interpret such sequences.
- Parameters
-
is the input stream ch the character read by DoRead s the string object that contains the token read
- Returns
- -1 in case of errors or EOF


|
protected |
Read a 4-hex-digit unicode character.
The function is called by ReadString() when the \u sequence is encontered; the sequence introduces a control character in the form:
where XXXX is a four-digit hex code.. The function reads four chars from the input UTF8 stream by calling ReadChar() four times: if EOF is encontered before reading four chars, -1 is also returned and no sequence interpretation is performed. The function stores the 4 hexadecimal digits in the uesBuffer parameter.
Returns the character after the hex sequence or -1 if EOF.
NOTICE: although the JSON syntax states that only control characters are represented in this way, the wxJSON library reads and recognizes all unicode characters in the BMP.


|
protected |
Read a value from input stream.
The function is called by DoRead() when it enconters a char that is not a special char nor a double-quote. It assumes that the string is a numeric value or a literal boolean value and stores it in the wxJSONValue object val.
The function also checks that val is of type wxJSONTYPE_INVALID otherwise an error is reported becasue a value cannot follow another value: maybe a (,) or (:) is missing.
If the literal starts with a digit, a plus or minus sign, the function tries to interpret it as a number. The following are tried by the function, in this order:
- if the literal starts with a digit: signed integer, then unsigned integer and finally double conversion is tried
- if the literal starts with a minus sign: signed integer, then double conversion is tried
- if the literal starts with plus sign: unsigned integer then double conversion is tried
Returns the next character or -1 on EOF.

|
protected |
Skip a comment.
The function is called by DoRead() when a '/' (slash) character is read from the input stream assuming that a C/C++ comment is starting. Returns the first character that follows the comment or -1 on EOF. The function also adds a warning message because comments are not valid JSON text. The function also stores the comment, if any, in the m_comment data member: it can be used by the DoRead() function if comments have to be stored in the value they refer to.

|
protected |
Skip all whitespaces.
The function reads characters from the input text and returns the first non-whitespace character read or -1 if EOF. Note that the function does not rely on the isspace function of the C library but checks the space constants: space, TAB and LF.


|
protected |
Store the comment string in the value it refers to.
The function searches a suitable value object for storing the comment line that was read by the parser and temporarly stored in m_comment. The function searches the three values pointed to by:
m_nextm_currentm_lastStored
The value that the comment refers to is:
- if the comment is on the same line as one of the values, the comment refer to that value and it is stored as inline.
- otherwise, if the comment flag is wxJSONREADER_COMMENTS_BEFORE, the comment lines are stored in the value pointed to by
m_next - otherwise, if the comment flag is wxJSONREADER_COMMENTS_AFTER, the comment lines are stored in the value pointed to by
m_currentor m_latStored
Note that the comment line is only stored if the wxJSONREADER_STORE_COMMENTS flag was used when the parser object was constructed; otherwise, the function does nothing and immediatly returns. Also note that if the comment line has to be stored but the function cannot find a suitable value to add the comment line to, an error is reported (note: not a warning but an error).


|
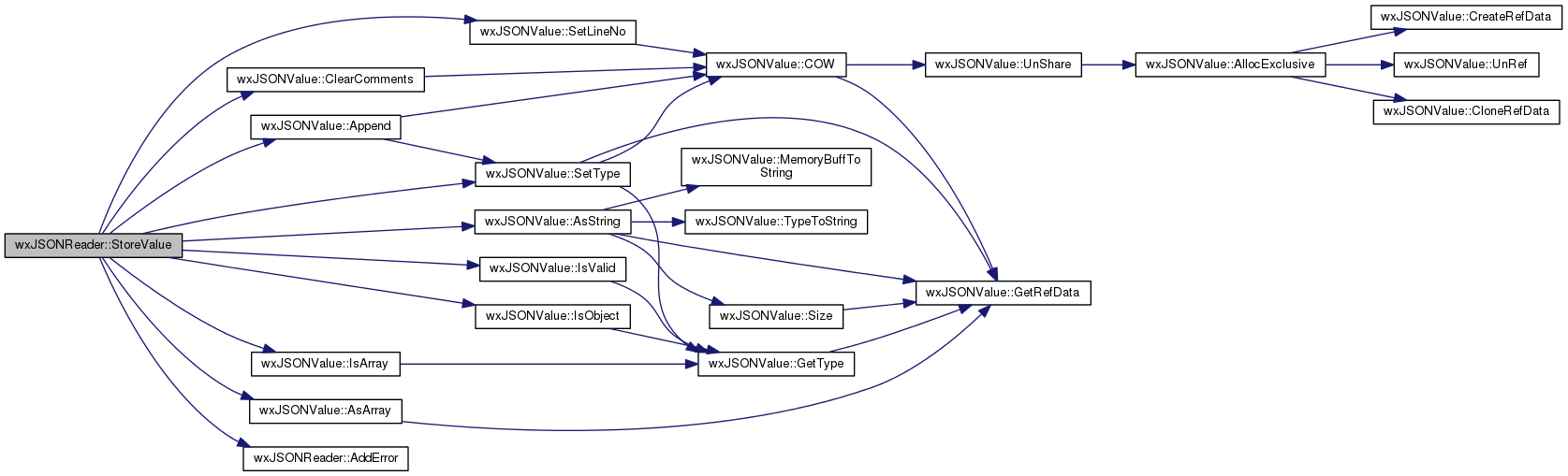
protected |
Store a value in the parent object.
The function is called by DoRead() when a the comma or a close-object/array character is encontered and stores the current value read by the parser in the parent object. The function checks that value is not invalid and that key is not an empty string if parent is an object.
- Parameters
-
ch the character read: a comma or close objecty/array char key the key string: must be empty if parentis an arrayvalue the current JSON value to be stored in parentparent the JSON value that is the parent of value.
- Returns
- none

|
static |
Compute the number of bytes that makes a UTF-8 encoded wide character.
The function counts the number of '1' bit in the character ch and returns it. The UTF-8 encoding specifies the number of bytes needed by a wide character by coding it in the first byte. See below.
Note that if the character does not contain a valid UTF-8 encoding the function returns -1.

The documentation for this class was generated from the following files:
- /home/bishop/work/projects/nextgismanager/include/wxgis/core/json/jsonreader.h
- /home/bishop/work/projects/nextgismanager/src/core/json/jsonreader.cpp
- Generated on Fri Sep 26 2014 01:11:05 for ngm by
 1.8.6
1.8.6